
Data transformations for grouping and joining data require all-to-all data transfers - called shuffle operations, are becoming the scaling bottleneck when running many small tasks in multi-stage data analytics jobs. The bottleneck is due to the superlinear increase in disk I/O operations as data volume increases.
Riffle’s key idea is to merge fragmented intermediate shuffle files into larger block files, converting small random I/O to large sequential ones. This greatly improved Facebook’s production Spark jobs’ number of shuffle I/O requests and end-to-end job completion time.
Motivation
Research work highly encourages running a large number of small tasks. Small tasks improve the parallelism, reduce the straggler effect with speculative execution, and speed up end-to-end job completion. However, this introduces significant I/O overhead during shuffle operations in multi-stage jobs.
Challenges
- Be efficient in handling shuffle files without using much computation or storage resources - overlaps the merge operations with map tasks, and best-effort merge
- Easy to configure - supports merge policies with different fan-ins and target block sizes
- Tolerate failures during merge and shuffle - keeps track of intermediate files in both merged and unmerged forms, allowing fall back in case of failure
- Should not create prohibitive overhead - by issuing all merge requests as large sequential requests
I/O Math: why I/O grows quadratically with data size
TL;DR: Disk spill is expensive. To avoid disk spills, we want the task input size of fit in memory. As the size of job data increases, the number of map (M) and reduce (R) tasks has to grow proportionally. As a result, the number of shuffle I/O requests M*R increases quadratically.
Existing Solutions
- Reducing the number of tasks: tuning each job is not scalable; bring additional I/O and garbage collection overhead; amplify the straggler problem
- Aggregation servers for reducers. 1. in-memory buffering aggregation: large resource overhead (large memory and computation); huge price of failure 2. new file system to support multiple insertion points to store aggregated intermediate files: compromising fault tolerance
Design and Implementation
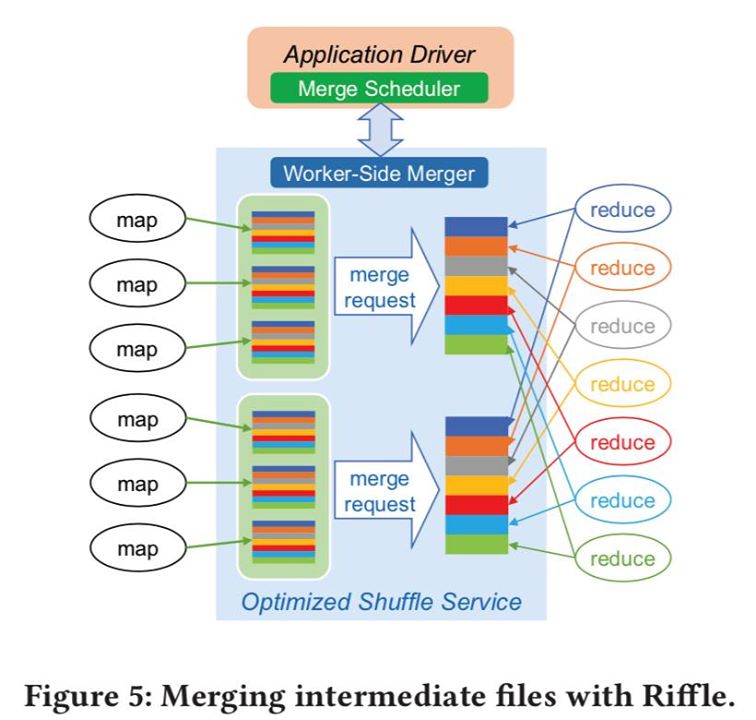
Riffle consists of a centralized scheduler that keeps track of intermediate shuffle files and dynamically coordinates merge operations, and a shuffle merge service which runs on each physical cluster node and efficiently merges the small files into larger ones with little resource overhead.
The merge scheduler starts merge operations immediately as map outputs become available, as a result, most merges to overlap with the ongoing map stage.
The Riffle scheduler avoids merging files that already have large blocks, and merges more files with tiny blocks for better I/O efficiency. Flexible policy: file and block based policies, allow Riffle to be applied to file systems with different I/O characteristics.
- Riffle merges compressed, serialized data files in their raw format on disks
- Mergers prefetch data from original shuffle files, aggregate the blocks belonging to same reducers, and asynchronously write blocks into the result file (For each shuffle file, the merger allocates a buffer for asynchronously reads and caches its index file, a separate buffer to asynchronously write the merged output file). This explains why small fragmented I/Os get converted to sequential ones

The merger estimates the memory consumption of processing the request based on the fan-in. When exceeding limit, new incoming merge requests will be queued up.
Because merge stragglers exist, best-effort merge is applied.
In case of merge failure, Riffle is designed to fall back to unmerged files, e.g., like best-effort, driver sends a mixture of metadata for merged and unmerged files to reduce tasks.
Load balancing: leverage “power of two choices”, e.g., each driver only needs to query the pending merge workload of two randomly picked mergers and choose the one with the shortest queue length.