Nowadays query performance is more determined by the raw CPU costs instead of I/O as memory grows. The classical iterator style query processing technique is very simple and flexible, but shows poor performance on modern CPUs due to lack of locality and frequent instruction mispredictions.
This work presents a strategy that translates a query into compact and efficient machine code using LLVM. Aiming at good code and data locality and predictable branch layout, the resulting code rivals the performance of handwritten C++ code with modest compilation time.
Motivation
Traditional query translation is processed in a volcano style: every physical algebraic operator conceptually produces a tuple stream from its input, and allows for iterating over this tuple stream by repeatedly calling the next function of the operator.
However, this iterator model has problems now as:
- The next function will be called for every single tuple produced as intermediate or final result, i.e., millions of times.
- The call to next is usually a virtual call or a call via a function pointer, which is more expensive than a regular call and degrades the branch prediction performance.
- This model results in poor code locality and complex book-keeping. Tuples have to be produced one at a time, and the table scan operator has to remember where in the compressed stream the current tuple is and jump to the corresponding decompression code when asked for the next tuple.
One improvement is to use some form of batch-oriented processing, which amortizes the invocation cost, and also allows vectorized operations, however lacks the pipelining ability — that an operator can pass data to its parent operator without copying or otherwise materializing the data. When producing more than one tuple during a call this pure pipelining usually cannot be used any more, as the tuples have to be materialized somewhere to be accessible. It has other advantages like allowing for vectorization, but it consumes more memory bandwidth. The fact is, hand-written program clearly outperforms even very fast vectorized systems.
Example
The principle is that all data should be kept in CPU registers as long as possible and maximize data and code locality. Instead of pulling tuples up, we push them towards the consumer operators. Below is a sample query along with its execution plan.
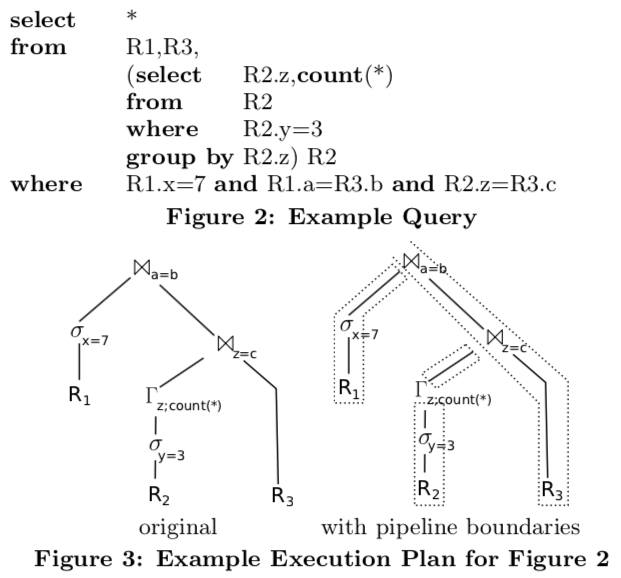
The SQL query selects some tuples from R2, groups them by z, joins the result with R3, and joins the result with some tuples from R1. In the classical model, the top-most join would produce tuples by first asking its left input for tuples repeatedly, placing each of them in a hash table, and then asking its right input for tuples and probing the hash table for each table. The input sides themselves would operate in a similar manner recursively. The right feature shows the materialization points. As we have to materialize the tuples anyway at some point, we propose to compile the queries in a way that all pipelining operations are performed purely in CPU (i.e., without materialization), and the execution itself goes from one materialization point to another.

Compilation
From the point of view of the query compiler the operators offer an interface that is nearly as simple as in the iterator model. Conceptually each operator offers two functions: produce() and consume(attributes, source)

Misc
The system is also taking advantage of SIMD using SIMD registers, which is some form of block-wise processing, and provides inter-tuple parallelism. Inter-query parallelism is similar to other database systems.
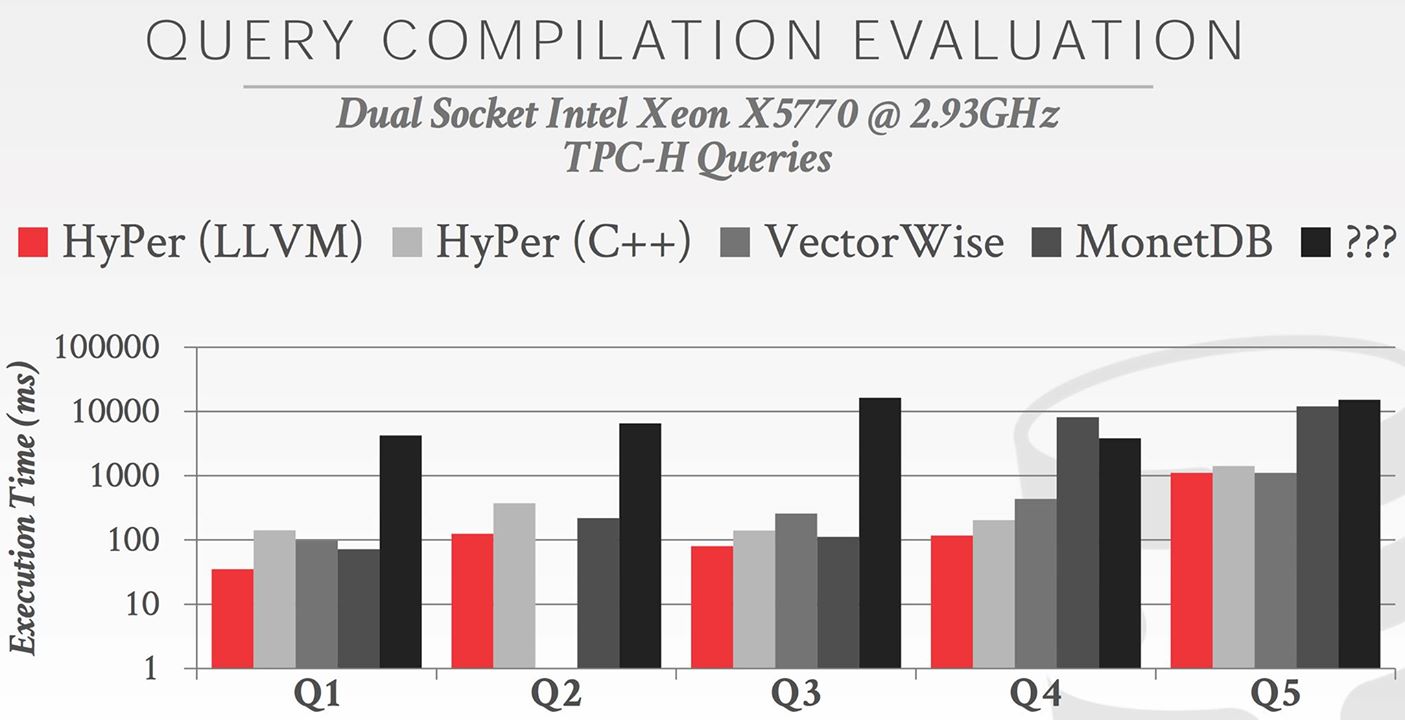
The result is Hyper with LLVM beats other competitors as it tries to organize data access in tight loops, resulting in good memory prefetching and accurate branch prediction.