
Optimization goals:
- Reduce Instruction Count
- Reduce Cycles per Instruction
- Parallelize Execution
CPUs organize instructions into pipeline stages. Super-scalar CPUs support multiple pipelines.
- Problem #1: Dependencies
- Problem #2: Branch Prediction: CPUs will speculatively execute branches. This potential hides the long stalls between dependent instructions.
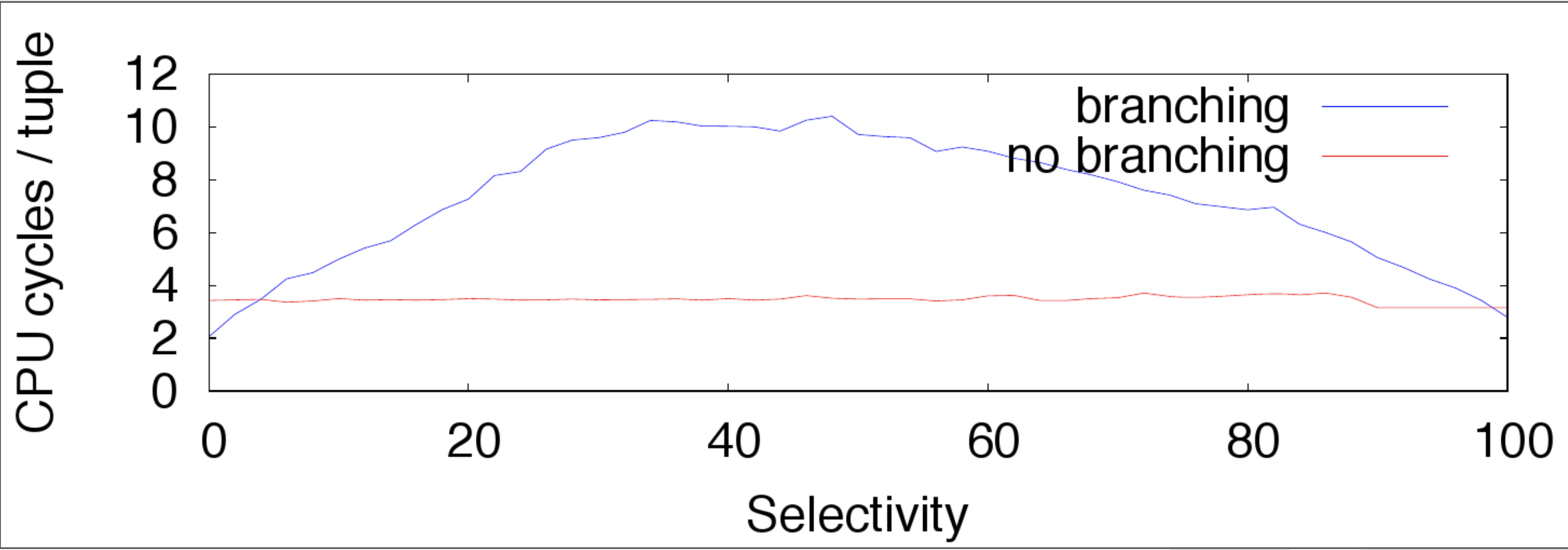
In selection scans, branching only outperforms branchless when selectivity is really high or really low.

Processing Model
Iterator Model
Each query plan operator implements a next function.
- On each invocation, the operator returns either a single tuple or a null marker if there ae no more tuples.
- The operator implements a loop that calls next on its children to retrieve their tuples and then process them.
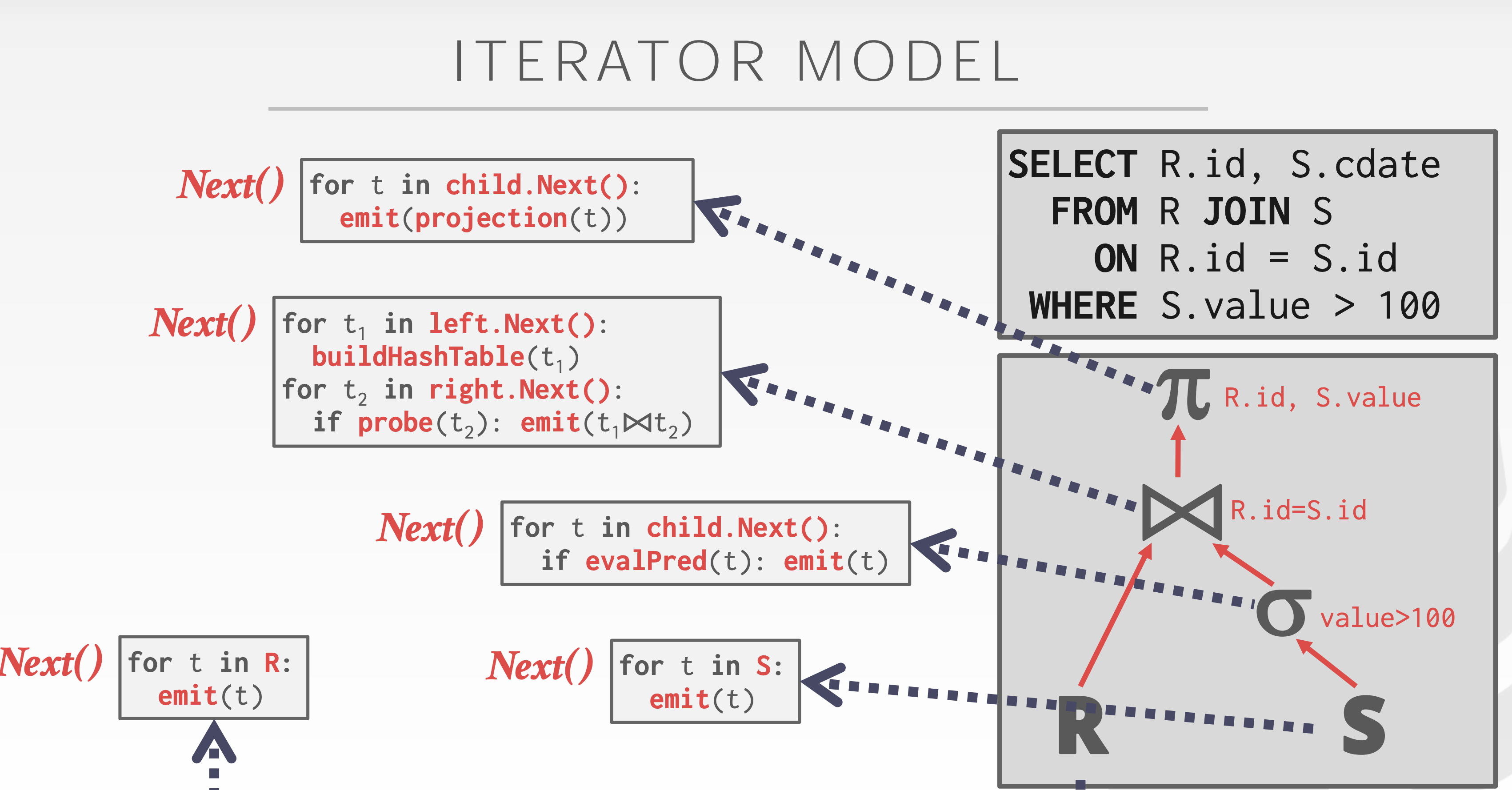
This is used in almost every DBMS. Allows for tuple pipelining. Some operators must block until their children emit all of their tuples.
Output control works easily wit this.
Materialization Model
Each operator processes its input all at once and then emits its output all at once.
- The operator “materializes” its output as a single result.
- The DBMS can push down hints to avoid scanning too many tuples.
- Can send either a materialized row or a single column.
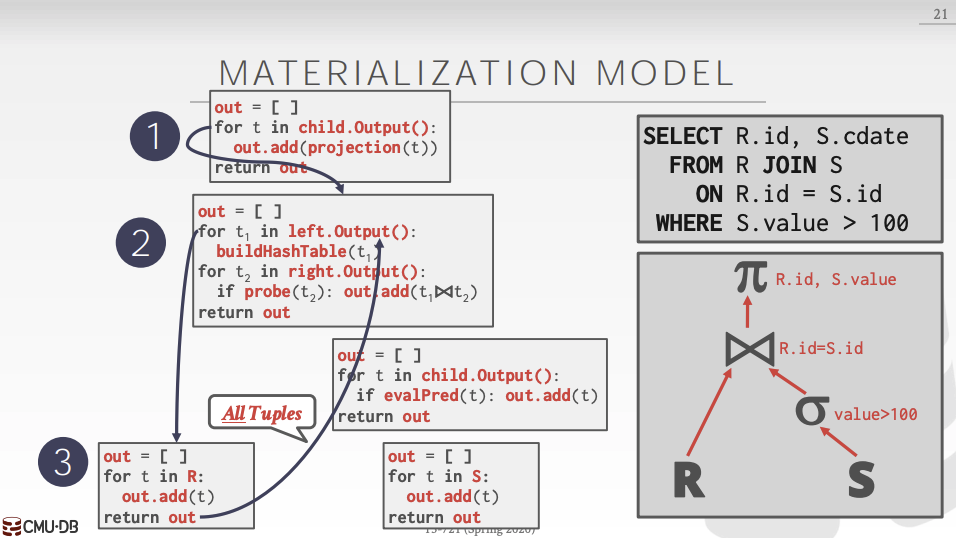
- Lower execution/coordination overhead.
- Fewer function calls.
Not good for OLAP queries with large immediate results.
Vectorized/Batch Model
Like iterator model, but each operator emits a batch of tuples instead of a single tuple. The operator’s internal loop processes multiple tuples at a time.
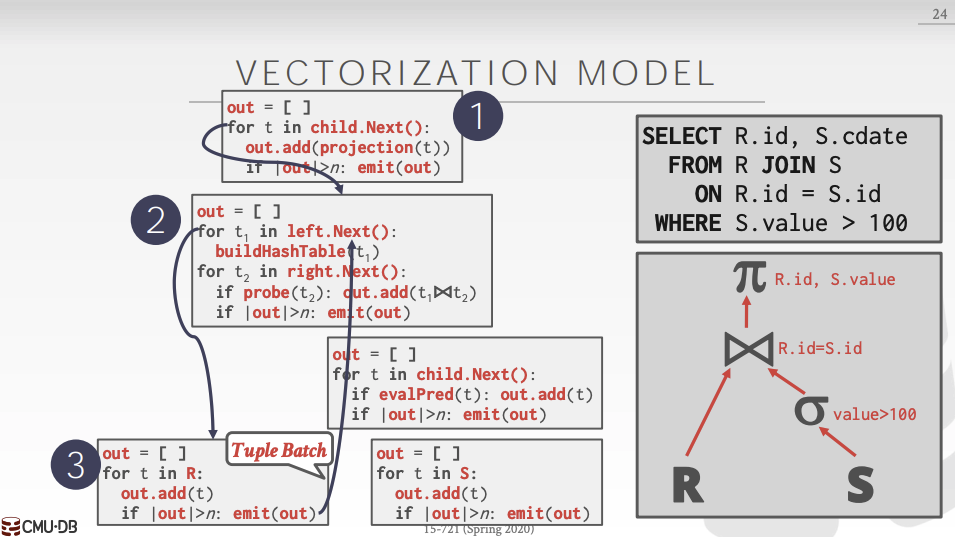
Ideal for OLAP queries because it greatly reduces the number of invocations per operator. Allows for operators to use SIMD instructions.
Plan Processing Direction
- Top-to-Bottom
- Start with the root and “pull” data up from its children.
- Tuples are always passed with function calls.
- Bottom-to-Top
- Start with leaf nodes and push data to their parents.
- Allows for tighter control of caches/registers in pipelines.