
The shared nature of analytics job services across several users and teams leads to significant overlaps in partial computations, i.e., parts of the processing are duplicated across multiple jobs, thus generating redudant costs.
- Reuse computations by creating materialized views over recurring workloads, i.e. periodically executing jobs that have the same script templates but process new data each time
- Select the views to materialize using a feedback loop that reconciles the compile-time and run-time statistics and gathers precise measures of the utility and cost of each overlapping computation
- Create materialized views in an online fashion, without requiring an offline phase to materialize the overlapping computations
Introduction
Almost 40% of the daily SCOPE jobs have computation overlap with one or more other jobs. Likewise, there are millions of overlapping subgraphs that appear at least twice. The ideal solution would be for the users to modularize their code and reuse the shared set of scripts and intermediate data, this is not possible in practice.
Challenges
- Feedback loop needs to reconcile the logical query trees with the actual runtime statistics to get more precise measures of utility and cost of each overalp.
- Halting or delaying recurring jobs to create materialized views is not an option. Need to create materialized views just in time and with minimal overheads.
Contributions
The goal is to alow users to write their jobs just as before, i.e., with zero changes to user scripts, and to automatically detect and reuse computations wherever possible.
First, we present detailed analysis of the computation reuse opportunity in our production clusters to get a sense of magnitude of the problem and the expected gains. Overlaps often occur at shuffle boundaries.
To enable computation reuse over recurring jobs, key idea is to use a combination of normalized and precise hashed (called signatures) for computation subgraphs.
The CLOUDVIEWS analyzer captures the set of interesting computations to reuse based on their prior runs, plugs in custom view selection methods to select the view to materialize given a set of constraints, picks the physical design for the materialized views, and also determines the expiry of each of the materialized views.
CLOUDVIEWS runtimes includes a metadata service for fetching the metadata of computations relevant for reuse in a given job, an online view materialization mechanism as part of job execution, a synchronization mechanism to avoid materializing the same view in parallel, making materialized views available early during runtime, automatic query rewriting using materialized views, and job coordiantion hints to maximize the computation reuse.
The REUSE opportunity
Why do we have computation overlap? 1. Users rarely start writing their analytics scripts from scratch, rather they start from other people’s scripts and extend/modify them to suit their purpose. 2. There is a data producer/consumer model, where multiple different consumers process the same inputs, and they often end up duplciating the same (partial or full) post-processing over those inputs.
Sort and exchange (shuffle) constitue the top two most overlapping computations. Observation is impact of computation reuse is very skewed — relatively few redumdancies have high frequencies, and relatively few redundancies have high computation/storage cost.
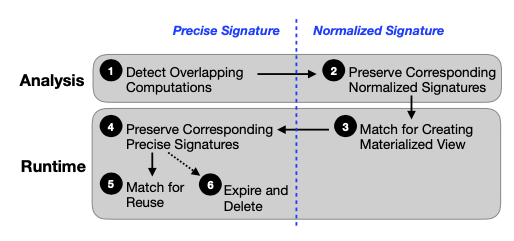
Automatic; Transparent; Correct; Latency-sensitive; Maximize reuse; Debuggability; Reporting. Two online components: a periodic workload analyzer to mine overlapping computations, and a runtime engine to materialize and resue those computations.
CLOUDVIEWS analyzer
(1) Providing feedback loop for runtime statistics (2) Picking the physical design for the selected views to materialize (3) Determining the expiry of a materialized view (4) Providing a user interface to tune and visualize the workload analysis
We restrict ourselves to common subgraphs, such that we are able to capture precise utility and cost estimates, no post-processing makes gains more predictable.
Physical design
Physical design is important because materialized views with poor physical design end up not being used because the computation savings get over-shadowed by any additional repartitioning or sorting that the system needs to do.
Try to extract physical properties when enumerating them, or infer from children if not available. Pick the most popular set.
Expirty and purging
Longest duration that it gets used by any recurring jobs is a good estimate of the view expiry. Or purge materialized views with minimum utility.
CLOUDVIEWS RUNTIME
Instead of lookup each subgraph, we make one request per job and fetch all overlaps that could be relevant for that job. This is done by creating an inverted index.
When trying to materialize an overlapping computation, it proposes the materialization to the metadata service, and create an exclusive lock to materialize this view.
Also supports view materialization offline.
When signature matches, the optimizer adds an alternate subexpression plan which reads from the materialized view.
Since multiple jobs containing the same overlapping computation could be scheduled concurrently, we deal with this by reordering recurring jobs in the client job submission systems. Pick the shortst job in terms of run time.
Evaludation
Note that view materialization can slow down queries because:
- Materialized view read costs could be significant and vairable based on the parallelsim used at runtime
- Accurate estimates are propagated only in the subexpression that uses a view and the estimates are still way off in other cases.
- There could be additional partitioning or sorting applid by the optimizer to satisfy the required physical properties of the parent subexpressions.
- Latency improvements depend on the degree to which the overlap is on the critical path.
Lessons learned
CLOUDVIEWS analyzer can be used as an offline tool. SLA-sensitive jobs can opt-out. We can pick the best physical design and reuse! Users don’t need to worry. Better reliability too — materilization can act as checkpointing. Input data change invalidates the data.
The author has a poster in VLDB ‘19, which shares a similar spirit: with an offline analyzer extract materialization candidates, logs the recurring and strict signatures, and adds two rules: Online Materialization and Computation Reuse.