
Use Cases
Interactive Analytics
Individual clusters are required to support 50-100 concurrent running queries with diverse query shapes, and return results within seconds or minutes. Users are highly sensitive to end- to-end wall clock time, and may not have a good intuition of query resource requirements. While performing exploratory analysis, users may not require that the entire result set be returned. Queries are often canceled after initial results are returned, or use LIMIT clauses to restrict the amount of result data the system should produce.
Batch ETL
Batch jobs tend to be much more resource intensive than queries in the Interactive Analytics use case, and often involve performing CPU-heavy transformations and memory-intensive (multiple TBs of distributed memory) aggregations or joins with other large tables. Query latency is somewhat less important than resource efficiency and overall cluster throughput.
A/B testing
Results must be computed on the fly. Producing results requires joining multiple large data sets, which include user, device, test, and event attributes. Query shapes are restricted to a small set since queries are programmatically generated.
Developer/Advertiser Analytics
A restricted set of query shapes. Data volumes are large in aggregate, but queries are highly selective, as users can only access data for their own applications or ads. Most query shapes contain joins, aggregations or window functions. Tooling meant to be interactive, have 99.999% availability and support hundreds of concurrent queries.
Architecture Overview
A single coordinator node and one or more worker nodes. Coordinator responsible for admitting, parsing, planning and optimizing queries as well as query orchestration. Worker nodes are responsible for query processing.
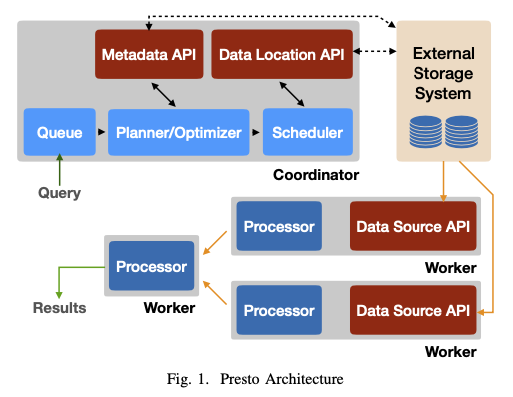
The client sends an HTTP request containing a SQL statement to the coordinator. The coordinator processes the request by evaluating queue policies, parsing and analyzing the SQL text, creating and optimizing distributed execution plan.
The coordinator distributes this plan to workers, starts exe- cution of tasks and then begins to enumerate splits, which are opaque handles to an addressable chunk of data in an external storage system. Splits are assigned to the tasks responsible for reading this data.
Worker nodes running these tasks process these splits by fetching data from external systems, or process intermediate results produced by other workers. Workers use co-operative multi-tasking to process tasks from many queries concurrently. Execution is pipelined as much as possible, and data flows between tasks as it becomes available. For certain query shapes, Presto is capable of returning results before all the data is processed. Intermediate data and state is stored in- memory whenever possible. When shuffling data between nodes, buffering is tuned for minimal latency.
System Design
Query Optimization
Presto contains several rules, including well-known optimizations such as predicate and limit pushdown, column pruning, and decorrelation.
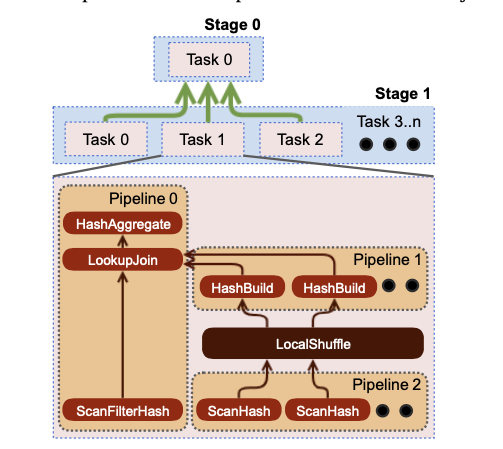
Intra-node Parallelism: The optimizer uses a similar mechanism to identify sections within plan stages that can benefit from being parallelized across threads. The engine can run a single sequence of operators (or pipeline) in muliple threads.
Scheduling
Data streams from stage to stage as soon as it is available.
To execute a query, the engine makes two sets of scheduling decisions. The first determines the order in which stages are scheduled, and the second determines how many tasks should be scheduled, and which nodes they should be placed on.
Presto supports two scheduling policies for stages: all-at_once and phased. All-at-once minimizes wall clock time by scheduling all stages of execution concurrently; data is processed as soon as it is available. This scheduling strategy benefits latency-sensitive use cases. Phased execution identifies all the strongly connected components of the directed data flow graph that must be started at the same time to avoid deadlocks and executes those in topological order.
Raptor is a storage engine optimized for Presto with a shared-nothing architecture that stores ORC files on flash disks and metadata in MySQL. Profiling shows that a majority of CPU time across our production clusters is spent decompressing, decoding, filtering and applying transformations to data read from connectors. This work is highly parallelizable, and running these stages on as many nodes as possible usually yields the shortest wall time. Therefore, if there are no constraints, and the data can be divided up into enough splits, a leaf stage task is scheduled on every worker node in the cluster.
Split Assignment
Presto asks connectors to enumerate small batches of splits, and assigns them to tasks lazily.
- Decouples query response time from the time it takes the connector to enumerate a large number of splits.
- Queries can start producing results without processing all the data. Such queries tend to be frequently cancelled quickly or complete early.
- Coordinator simply assigns new splits to tasks with the shortest queue. Keeping these queues small allows the system to adapt to variance in CPU cost of of processing different splits and performance differences among workers.
- Allow queries to execute without having to hold all their metadata in memory.
Once a split is assigned to a thread, it is executed by the driver loop. Every iteration of the loop moves data between all pairs of operators that can make progress. The unit of data that the driver loop operates on is called a page, which is a columnar encoding of a sequence of rows. The driver loop continuously moves pages between operators until the scheduling quanta is complete or until operators cannot make progress.
Shuffles
Presto uses in-memory buffered shuffles over HTTP to exchange in- termediate results. Data produced by tasks is stored in buffers for consumption by other workers. Workers request intermedi- ate results from other workers using HTTP long-polling.
Writes
PResto uses an adaptive approach, dynamically increasing writer concurrency when the stage producing data exceeds a buffer utilization threshold.
Resource Management
CPU Scheduling
Presto primarily optimizes for overall cluster throughput, i.e. aggregate CPU utilized for processing data. The local (node-level) scheduler additionally optimizes for low turnaround time for computationally inexpensive queries, and the fair sharing of CPU resources amongst queries with similar CPU requirements.
When a split relinquishes a thread, the engine needs to decide which task (associated with one more splits to run next). Presto simply uses a task’s aggregate CPU time to classify it into the five levels of a multi-level feedback queue. As tasks accumulate more CPU time, they move to higher levels. Presto gives higher priority to queries with lowest resource consumption.
Memory Management
Queries that exceed a global limit (aggregated across workers) or per-node limit are killed. We overcommit memory via:
Spilling
When a node runs out of memory, the engine invokes the memory revocation procedure on eligible tasks in ascend- ing order of their execution time, and stops when enough memory is available to satisfy the last request. Revocation is processed by spilling state to disk.
Reserved Pool
When the general pool is exhausted on a worker node, the query using the most memory on that worker gets ‘promoted’ to the reserved pool on all worker nodes. To prevent deadlock (where different workers stall different queries) only a single query can enter the reserved pool across the entire cluster. If the general pool on a node is exhausted while the reserved pool is occupied, all memory requests from other tasks on that node are stalled. The query runs in the reserved pool until it completes, at which point the cluster unblocks all outstanding requests for memory.
Query Optimizations
Presto generates bytecode to natively deal with constants, function calls, references to variables, and lazy or short-circuiting operations. Bytecode generation improves the engine’s ability to store intermediate results in registers or caches rather than in memory