DataFrame和RDD相比多了数据特性,拥有Schema信息;而Dataset进一步提供了类型安全和面向对象的编程接口。
Unresolved LogicalPlan -> Analyzed LogicalPlan -> Optimized LogicalPlan -> Iterator[PhysicalPlan] -> SparkPlan -> Prepared SparkPlan
InternalRow用来表示一行行数据的类。
- BaseGenericRow 抽象类,实现了InternalRow中定义的所有get类型方法
- JoinedRow 两个InternalRow放在一起形成新的InternalRow
- UnsafeRow 不用Java对象存储方式,避免GC
TreeNode类是Spark SQL中所有树的基类,定义了一系列通用的集合操作和树便利操作接口。提供一种泛型,包含了两个子类QueryPlan和Expression体系。树的修改都是以替换已有节点的方式进行的:
- transformDown 用先序遍历方式规则作用于所有节点
- transformUp 用后序遍历方式将规则作用于所有节点
- …
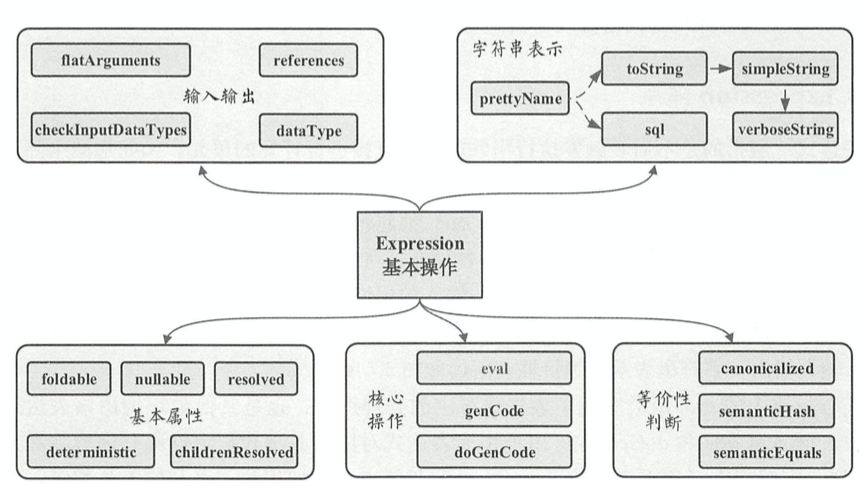
Expression
- foldable 用来标记表达式能否在查询执行之前直接静态计算。1. 该表达式为Literal 2. 子表达式foldable均为true
- deterministic 每次eval的输出是否都相同
- nullable 标记表达式是否可能输出Null值,一般在生成的Java代码中对相关条件进行判断
- references 返回AttributeSet类型,表示该Expression中会涉及的属性值,默认情况为所有子节点中属性值的集合
- canonicalized 规范化后的表达式,去除Expr Id等等
- semanticEquals 判断语义上是否等价