
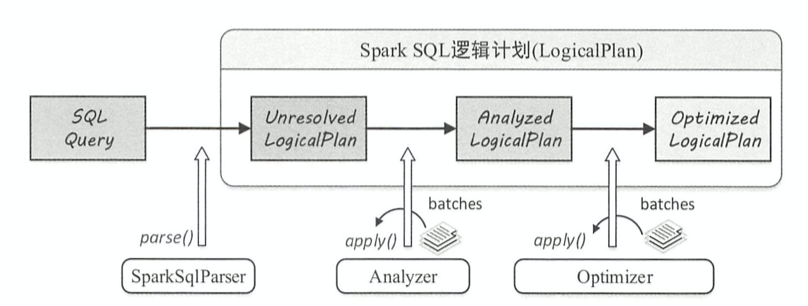
Logical Plan
在Spark SQL系统中,Catalog主要用于管理各种函数信息和元数据信息(数据库、数据表、数据视图、数据分区与函数等)的统一管理。包含:
- GlobalTempViewManager
- FunctionResourceLoeader
- FunctionRegistry
- ExternalCatalog
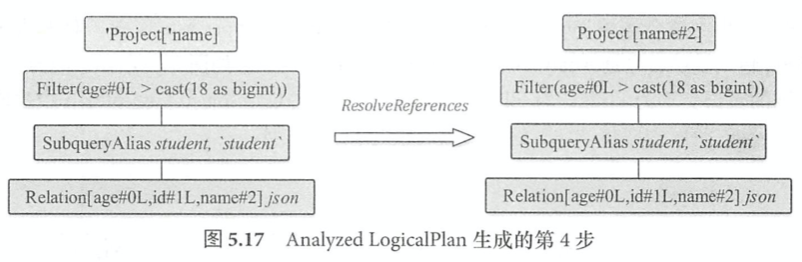
字符串形态的SQL语句转换为树形态的逻辑算子树,SQL中所包含的各种处理逻辑(过滤、剪裁等)和数据信息都会被整合在逻辑算子树的不同节点中。本质是一种中间过程表示,与Spark平台无关,后续阶段会被进一步映射为可执行的物理计划。
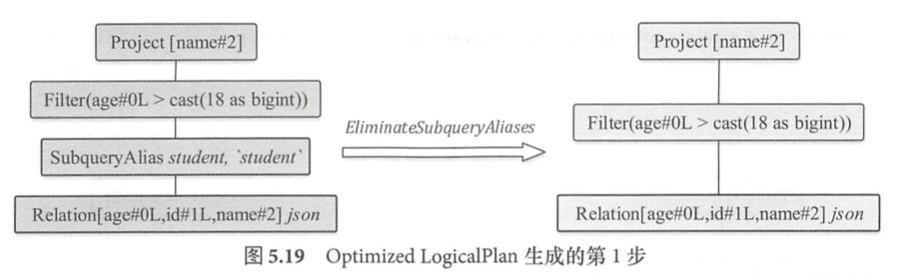
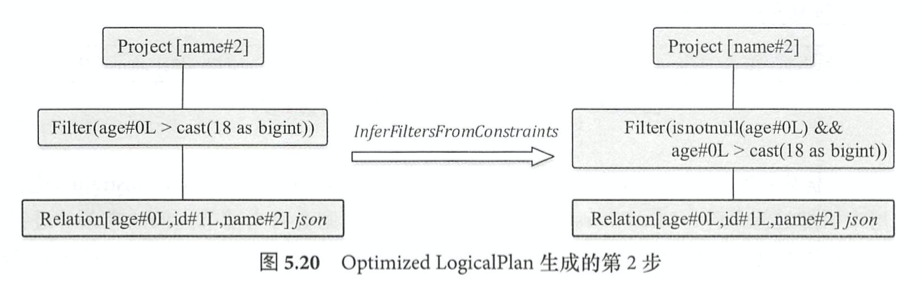
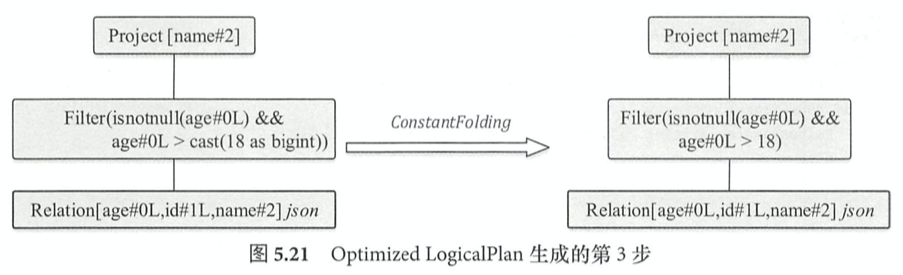
Batch Operator Optimizations中包含的主要类型是Operator Push Down,Operator Combine,Constant Folding and Strength Reduction.
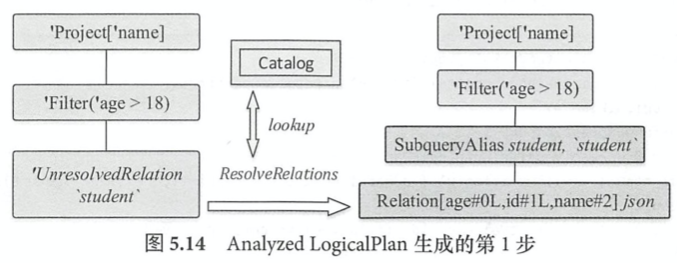
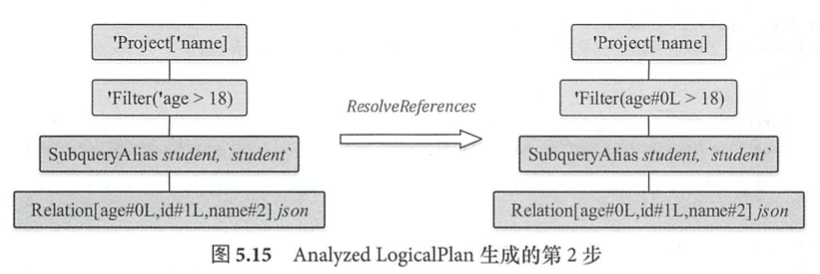
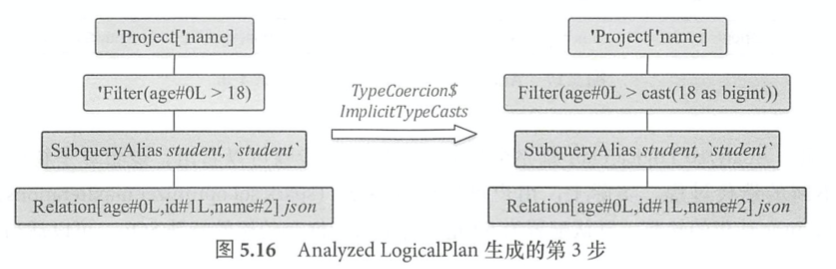
select name from student where age > 18
Physical Plan
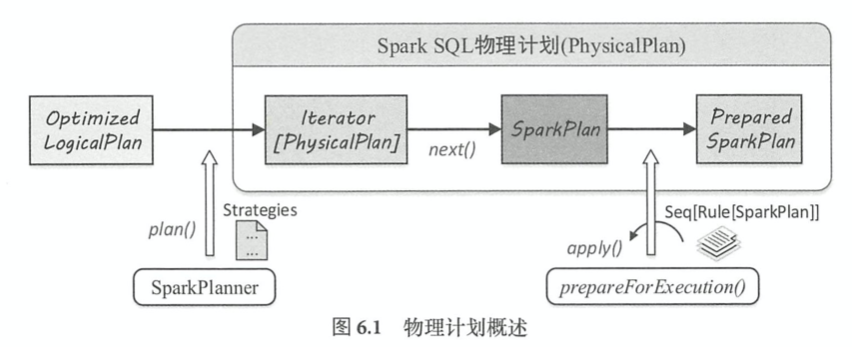 (1) Apply physical plan strategies to LogicalPlan nodes, and executes a list of SparkPlans
(2) Choose a best SparkPlan
(3) 进行一些分区排序方面的处理,确保SparkPlan各节点能够正确执行
(1) Apply physical plan strategies to LogicalPlan nodes, and executes a list of SparkPlans
(2) Choose a best SparkPlan
(3) 进行一些分区排序方面的处理,确保SparkPlan各节点能够正确执行
每个非叶子类型的SparkPlan节点等价于在RDD上进行一次Transformation,即通过调用execute()函数转换成新的RDD,最终执行collect()操作触发计算,返回结果给用户。SparkPlan的主要功能可以划分为3大块。首先,每个SparkPlan节点必不可少地记录其Metadata和Metric;其次,对RDD进行Transformation时,涉及Partitioning与Ordering;最后,SparkPlan执行操作,以execute和executeBroadcast为主。
LeafExecNode
基本是各类数据源节点,比如FileSourceScanExec, RangeExec, HiveTableScanExec生成对应的RDD
UnaryExecNode
UnaryExecNode主要是对RDD进行转换操作,例如ProjectExec, FilterExec, Exchange, SampleExec, SortExec和WholeStageCodegenExec.
BinaryExecNode
BroadcastHashJoinExec, BroadcastNestedLoopJoinExec, CartesianProductExec, CoGroupExec, ShuffledHashJoinExec, SortMergeJoinExec
其他类型的SparkPlan
比如CodeGenSupport, UnionExec
Spark Plan
Partitioning和Ordering体系起到承前启后的作用。requiredChildDistribution和requiredChildOrdering规定了当前SparkPlan所需的数据分布和数据排序方式列表,而outputPartitioning和outputOrdering则定义了每个数据分区的分区操作和每个数据分区的排序方式。
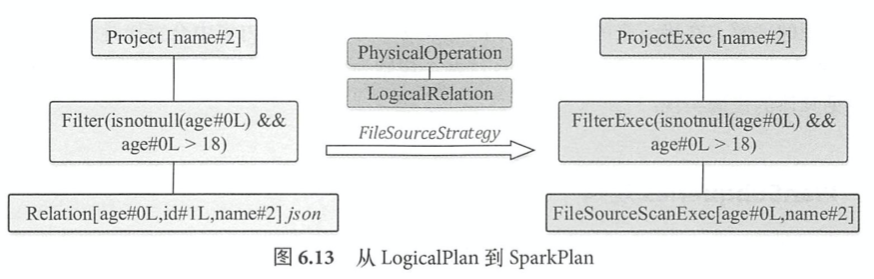
SparkStrategies逻辑驱动,各种策略的apply方法将Logical Plan映射成Physical Plan算子,最后得到一个物理计划的列表,包含FileSourceStrategy, Aggregation, JoinSelection和DDLStrategy等等。
执行前准备,prepareForExecution对传入的SparkPlan进行处理而生成executedPlan,执行若干规则,例如PlanSubqueries, EnsureRequirements, CollapseCodegenStages, ReuseExchange, ReuseSubquery等。
EnsureRequirements在物理计划中添加一些shuffle操作或排序操作来达到要求。遍历SparkPlan时,匹配到Exchange节点(ShuffleExchange)且其子节点也是Exchange类型时,会检查两者的Partitioning方式,判断能否消除多余的Exchange节点。大致分为以下3步: (1) 添加Exchange节点:当数据分布不满足或者数据分布不兼容。 (2)