
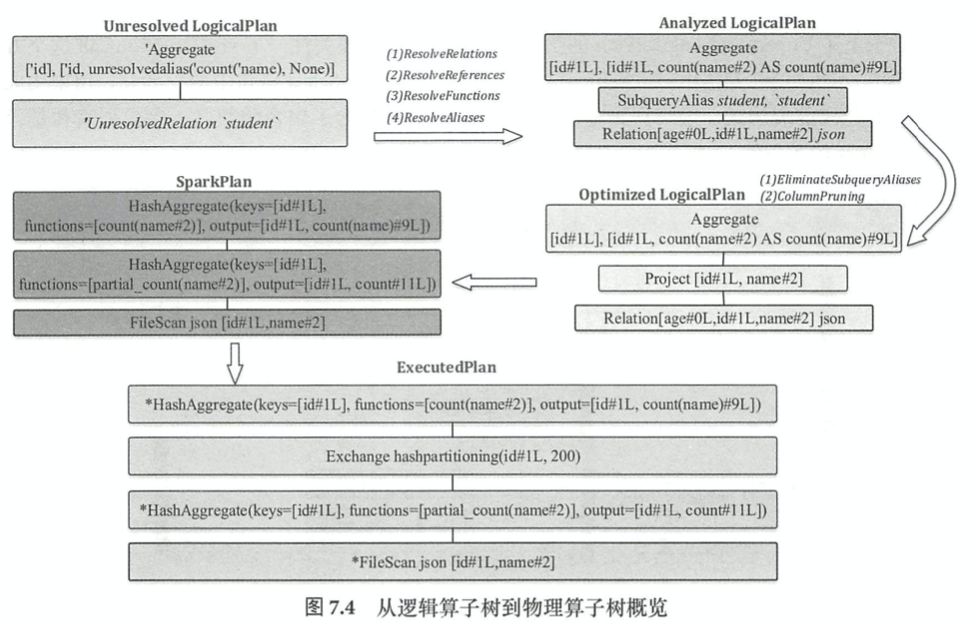
select id, count(name) from student group by id
 Aggregation有三个策略:
(1) planAggregateWithoutPartial
(2) planAggregateWithoutDistinct
(3) planAggregateWithOneDistinct
Aggregation有三个策略:
(1) planAggregateWithoutPartial
(2) planAggregateWithoutDistinct
(3) planAggregateWithOneDistinct
聚合函数AggregateFunction
- 聚合函数缓冲区:同一个分组的数据聚合过程中,用来保存聚合函数计算中间结果的缓存空间。
- 聚合模式:包含四种,Partial/PartialMerge/Final/Complete
DeclarativeAggregate聚合函数: initialValues, updateExpressions, mergeExpressions, evaluateExpression
ImperativeAggregate聚合函数: 聚合缓冲区是共享的,对应多个聚合函数,因此特定的ImperativeAggregate聚合函数会通过偏移量进行定位。本质上是基于InternalRow的。
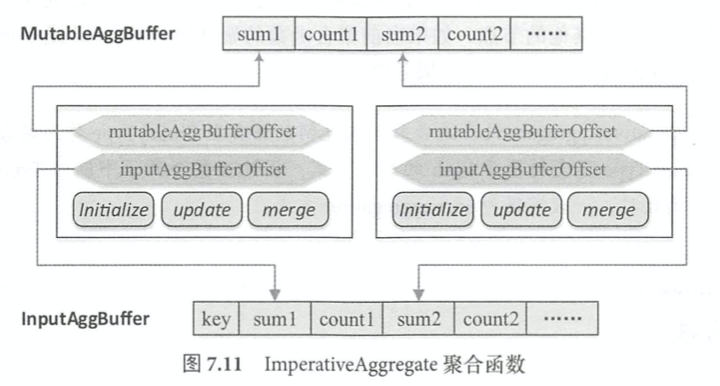 TypedImperativeAggregate聚合函数:
(1) 初始化聚合缓冲区对象。initialize执行createAggregationBuffer函数来获得初始化的缓冲区对象
(2) 处理输入的数据行。Partial/Complete -> update; PartialMerge/Final -> merge.
(3) 输出结果。如果聚合函数的聚合模式是Partial/PartialMerge,执行框架会调用serializeAggregateBufferInPlace把全局缓冲区中的Java对象替换为序列化后的二进制数据,并shuffle到其他的节点。如果聚合模式是Final/Complete,则执行框架会用eval计算最终结果
TypedImperativeAggregate聚合函数:
(1) 初始化聚合缓冲区对象。initialize执行createAggregationBuffer函数来获得初始化的缓冲区对象
(2) 处理输入的数据行。Partial/Complete -> update; PartialMerge/Final -> merge.
(3) 输出结果。如果聚合函数的聚合模式是Partial/PartialMerge,执行框架会调用serializeAggregateBufferInPlace把全局缓冲区中的Java对象替换为序列化后的二进制数据,并shuffle到其他的节点。如果聚合模式是Final/Complete,则执行框架会用eval计算最终结果
聚合执行
通常采用HashAggregate,以下情况使用SortAggregate
- 有聚合函数不支持partial aggregation
- 聚合函数结果不支持buffer方式
- 内存不足 ObjectHashAggregation见SPARK-17949
SortAggregateExec: 进行聚合前,会根据grouping key进行分区并在分区内排序将具有相同grouping key的记录分部在同一个partition内且前后相邻。聚合时只需要顺序遍历整个分区内的数据,即可得到聚合结果。
 HashAggregateExec: This iterator first uses hash-based aggregation to process input rows. It uses a hash map to store groups and their corresponding aggregation buffers. If this map cannot allocate memory from memory manager, it spills the map into disk and creates a new one. After processed all the input, then merge all the spills together using external sorter, and do sort-based aggregation.
HashAggregateExec: This iterator first uses hash-based aggregation to process input rows. It uses a hash map to store groups and their corresponding aggregation buffers. If this map cannot allocate memory from memory manager, it spills the map into disk and creates a new one. After processed all the input, then merge all the spills together using external sorter, and do sort-based aggregation.

窗口函数
窗口函数可以通过计算每行周围窗口上的集合值来分析数据。输入和输出行相等:类似Group By的聚合,支持非顺序的数据访问;可以对窗口函数使用分析函数、聚合函数和排名函数;简化了SQL代码并可以避免中间表。
窗口函数包含三个核心元素,分别是分区(PARTITION|DISTRIBUTE BY)、排序((ORDER|SORT) BY)和窗框(windowFrame)。 e.g.
select studentID, row_num() over (partition by gradeID, classID order by score desc) as ranking from exam
多维查询
Cube =
select gradeID, classID, max(score) from exam group by gradeID, classID
union
select gradeID, null, max(score) from exam group by gradeID, null
union
select null, classID, max(score) from exam group by null, classID
union
select null, null, max(score) from exam group by null, null
Rollup =
select gradeID, classID, max(score) from exam group by gradeID, classID
union
select gradeID, null, max(score) from exam group by gradeID, null
union
select null, null, max(score) from exam group by null, null;
Grouping sets ((gradeID, classID), gradeID) =
select gradeID, classID, max(score) from exam group by gradeID, classID
union
select gradeID, null, max(score) from exam group by gradeID, null
Join查询执行
- BroadcastHashJoin
- ShuffledHashJoin
- SortMergeJoin
- BroadcastNestedLoopJoin
- CartesianProduct