
Tungsten旨在从内存和CPU层面对Spark的性能进行优化,主要包括3个方面:memory management and binary processing, cache-aware computation, code generation.
内存管理与二进制处理
Tungsten设计了一套内存管理机制,Spark可以直接操作二进制数据而不是JVM对象,使得内存使用效率大幅提升。Spark为数据存储和计算执行提供了统一的内存管理接口MemoryManager. 从Spark1.6开始,Spark默认采用统一内存管理UnifiedMemoryManager方式,存储内存和计算内存能够共享一个空间,并且可以动态地使用彼此的空闲区域。
Spark内存管理基本概念和MemoryManager
MemoryManager将内存模式分为堆内onheap和堆外offheap。
- Offheap: spark internal data structures (joins, aggregates etc.)
- Onheap: user allocations (UDFs/UDAFs/UDTFs etc.), reader/writer
- Storage Memory: cache; can also be allocated offheap
像spark.driver.memory和spark.executor.memory配置的都是堆内内存。使用包括,缓存RDD的数据或广播变量、执行Join或者Aggregation计算任务时进行shuffle操作等。同一个Executor中并发运行的多个task会共享Executor进程的JVM内存。堆内内存的申请与释放在本质上都是由JVM完成的,因此Spark不能精准控制堆内内存的申请和释放,不能摆脱GC开销,但对存储内存和执行内存各自独立的规划管理,一定程度上可以提升内存的利用率,减少异常的出现。
因此Spark用到了堆外offheap内存,直接在集群的系统内存中开辟空间,存储经过序列化的二进制数据。Spark基于JDK自带的Unsafe API实现了堆外内存的管理。堆外内存可以被精确地申请和释放,而且序列化的数据占用的空间可以被精确计算。
MemoryManager通过内存池机制管理内存。MemoryPool包括StorageMemoryPool和ExecutionMemoryPool,内部又分为onHeap和offHeap。
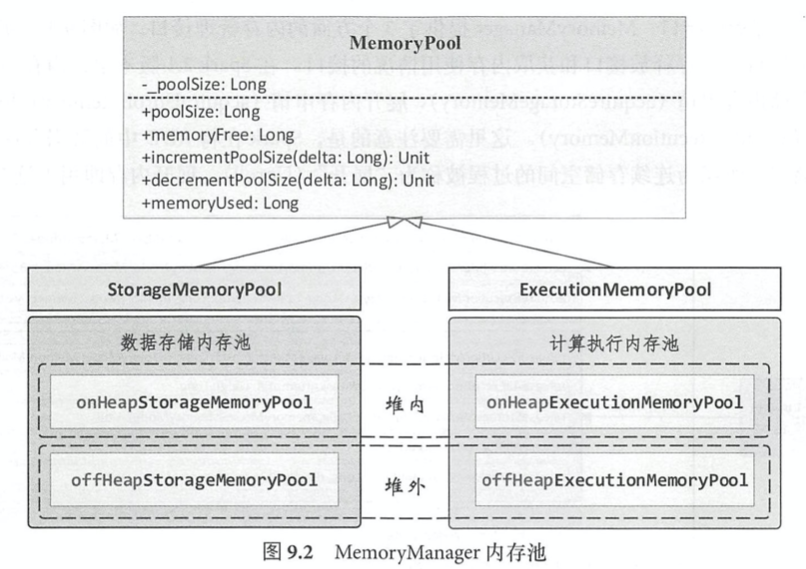
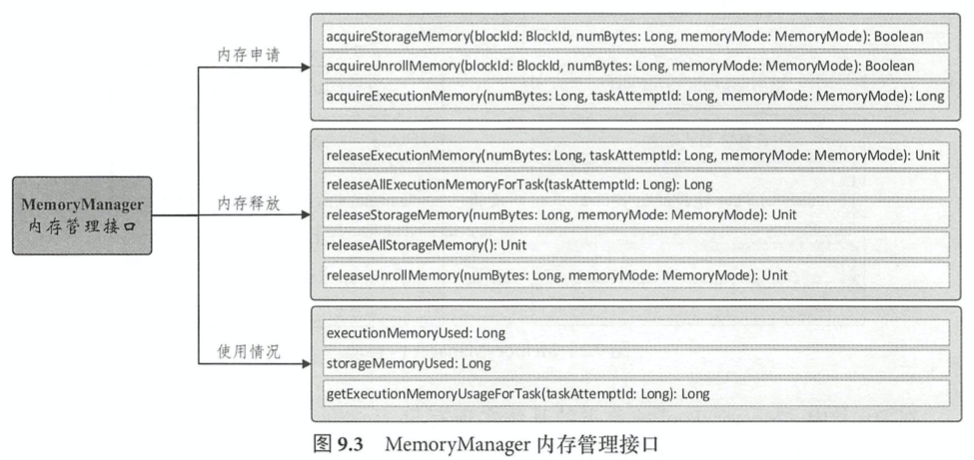
MemoryManager提供3个方面的内存管理接口,内存申请,内存释放和获取内存使用情况。Spark将RDD中的数据分区由不连续的存储空间组织为连续存储空间的过程被称为Unroll。
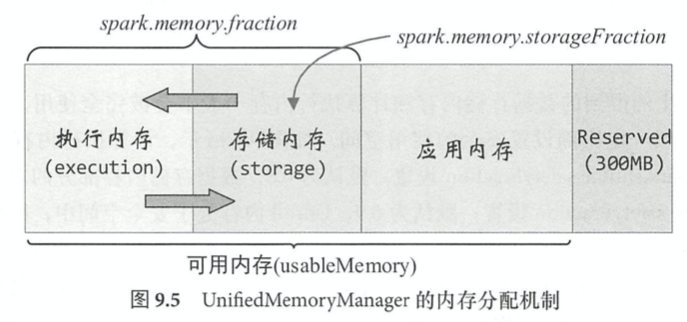
Reserved memory: 300MB, user memory, execution/storage memory. 两边可以动态借用:execution memory被对方占用后,可让对方将占用的部分转存到硬盘,然后归还借用的空间;但storage memory被对方占用后,无法让对方归还。
Storage Memory
(broadcasted things are put into storage memory)
acquireMemory最后调用的是evictBlocksToFreeSpace回收相应的内存空间。当execution需要借内存时,freeSpaceToShrinkPool可以收缩storage memory。
Spark的存储模块是BlockManager: provides interfaces for putting and retrieving blocks both locally and remotely into various stores (memory, disk, and off-heap). Driver端的BlockManager负责对全部Block的metadata进行管理和维护,Executor端的BlockManager将Block的更新等状态上报到Driver端,并接受主节点的相关命令。
Spark的RDD在缓存到存储内存之前,对象实例都处于JVM堆内内存的Other部分,即便同一个分区的数据在内存空间中也是不连续的,上层通过iterator来访问。当RDD持久化到storage memory后,Partition对应转换为Block,此时数据在storage memory内onheap/offheap连续存储。根据存储级别,Block也有序列化和非序列化两种存储形式。在展开时,对于序列化的Partition,空间可以直接计算,一次申请;非序列化的partition在遍历过程中依次申请。
同一个Executor的所有task共享存储内存。Eviction时新旧Block不属于同一个RDD,旧RDD不处于被读状态;LRU进行淘汰,根据存储级别,要么序列化后存储到磁盘,要么直接删除Block.
Execution Memory
Executor内所有task共享执行内存,如果正在执行的task数是n,那么每个任务可占用的内存大小为[1/2n, 1/n]。执行内存主要用于满足Shuffle/Join/Sort/Aggregation等计算过程对内存的需求。
ShuffleMapTask中会根据(partitionId, key)对所有的key-value进行排序,并把所有分区的数据写在一个文件中,同时也会建立一个index file来记录每个分区的大小和偏移。
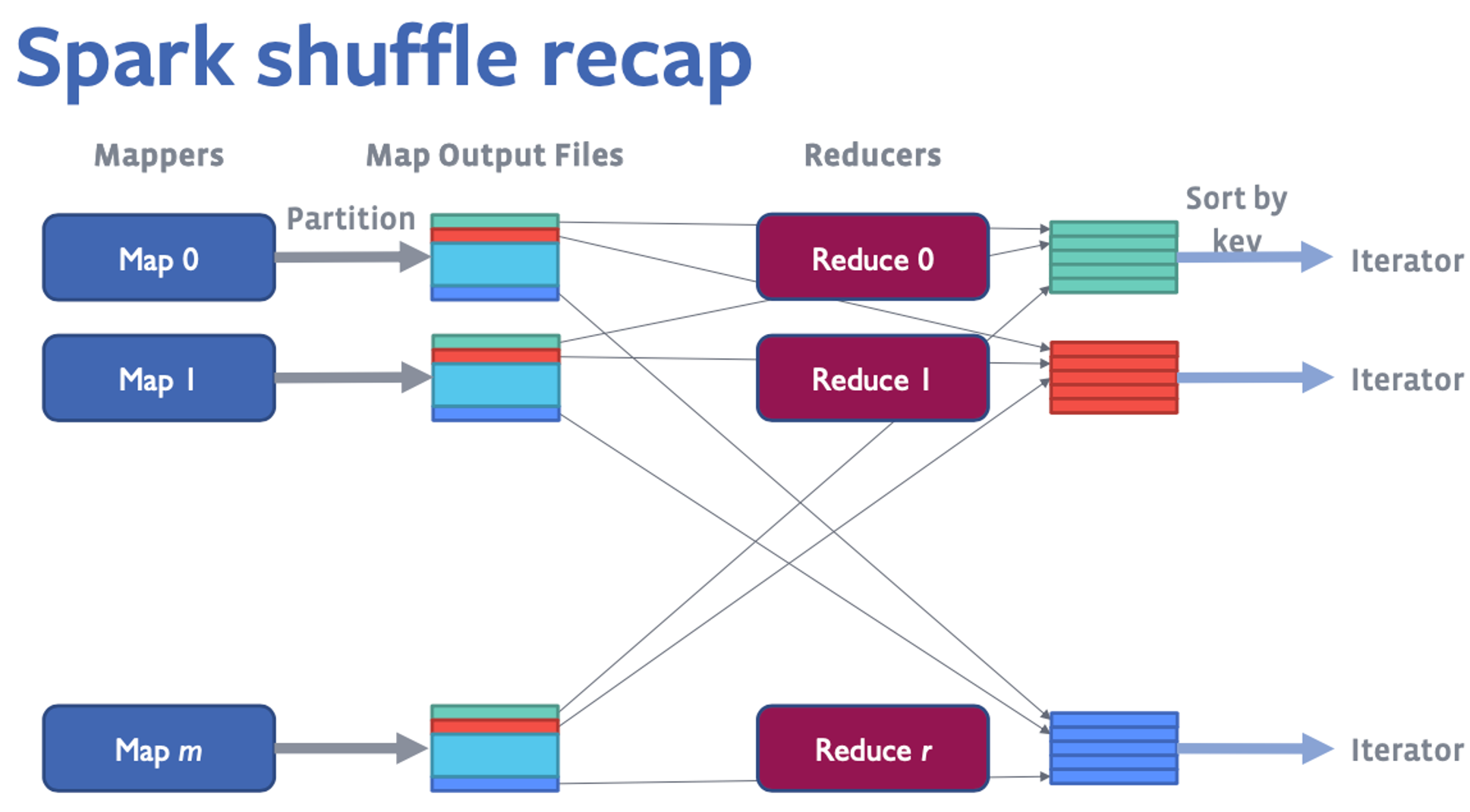
- BypassMergeSortShuffleHandle: 在shuffle partition数量很小而且不需要mapper side combine的时候,每个block写入单独的文件最后合并
- SerializedShuffleHandle: 输出数据先serialize成二进制数据存储在内存中。
- BaseShuffleHandle: 以deserialized format处理shuffle输出数据
SortShuffleWriter的write方法实现分为三步:
- 创建ExternalSorter对象,将全部数据插入
- 生成Shuffle数据文件和索引文件
- 创建MapStatus对象,将Shuffle数据文件和索引文件的信息进行创术,这样Shufle数据读取阶段能够知道从哪些节点获取哪些数据
如果有mapper side combine,那么分区内部也sort;反之不用sort. 如果没有定义Aggregator: 数据会存储到PartitionedPairBuffer这个动态扩容数组中,插入((partitionId, K), V) ,每次插入一条数据后都会调用maybeSpillCollect,申请不到memory就spill.
- Shuffle Write: 如果map端采用普通的排序方式,会用ExternalSorted进行外排,在内存中存储数据时主要占用堆内执行空间。如果map端采用Tungsten的排序方式,则采用ShuffleExternalSorter直接对serialized data进行排序,占用堆内或者堆外空间
- Shuffle Reader: reduce端聚合时数据交给Aggregator处理,在内存中存储数据时占用堆内执行空间。如果需要最终结果排序,数据交给ExternalSorter处理,占用堆内执行空间。
Tungsten内存管理优化基础
两个动机:
- Java对象占用内存空间大,比如”abcd”在UTF-16编码下需要8bytes,再加上内存布局的其他信息,共需要48bytes
- JVM GC overhead
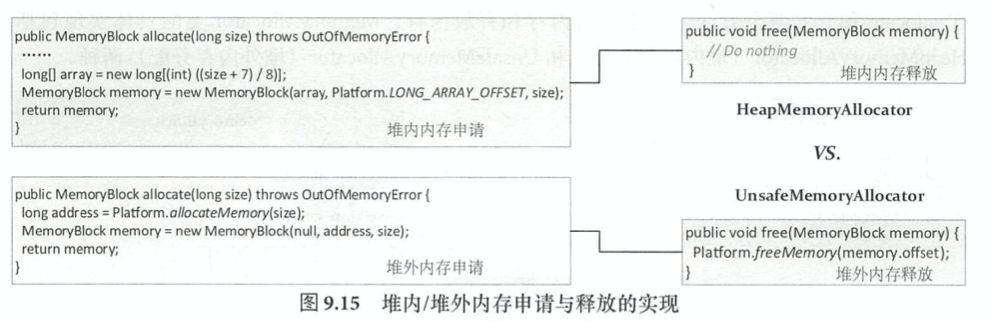
内存管理的基础是MemoryAllocator,包括HeapMemoryAllocator和UnsafeMemoryAllocator. 堆内内存由一个64bit的对象引用和该对象内部的偏移量表示;堆外通过类似malloc方法分配内存,进行精准的内存管理。Spark中堆外内存访问通过JDK的unsafe包提供,包括分配内存、释放内存和内存指针操作等,内存地址通过一个64bit的指针表示。
Spark中定义MemoryLocation来统一记录和追踪堆内、堆外的内存地址(有一个64bit的offset,堆外的对象引用为null)。MemoryBlock用来表示连续的内存块,在MemoryLocation的基础上增加了pageNumber和length. 如图,本质上HeapMemoryAllocator只是以8字节对齐申请长整形数组,内存释放由JVM GC处理;UnsafeMemoryAllocator直接过通过native调用来allocate/free memory.
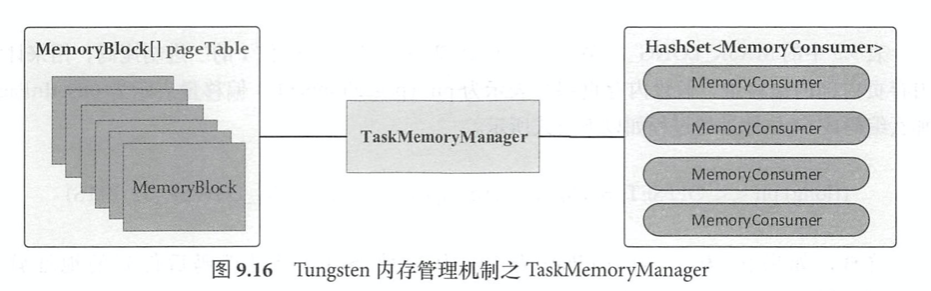 Tungsten按内存页表pageTable来管理内存,pageTable本质上是一个MemoryBlock的数组。每个Task的内存空间被划分为多个内存页page,每个内存页本质上都是一个内存块MemoryBlock。TaskMemoryManager引入了类似操作系统中虚拟内存逻辑地址的概念,将logical address映射到实际的physical address. 高位的13bits来表示page number,低位的51bits来表示offsetsInPage。这个内存映射过程还是根据内存页编号查询页表,得到对应的内存页,然后得到该页的物理地址,最后在物理地址上加上便宜得到实际物理地址。因此所有内存地址可由pageNumber和offsetInPage决定。对于堆外内存,可以类似指针一样直接访问数据,但是堆内因为GC原因Java对象的内存地址不是固定不变的。
Tungsten按内存页表pageTable来管理内存,pageTable本质上是一个MemoryBlock的数组。每个Task的内存空间被划分为多个内存页page,每个内存页本质上都是一个内存块MemoryBlock。TaskMemoryManager引入了类似操作系统中虚拟内存逻辑地址的概念,将logical address映射到实际的physical address. 高位的13bits来表示page number,低位的51bits来表示offsetsInPage。这个内存映射过程还是根据内存页编号查询页表,得到对应的内存页,然后得到该页的物理地址,最后在物理地址上加上便宜得到实际物理地址。因此所有内存地址可由pageNumber和offsetInPage决定。对于堆外内存,可以类似指针一样直接访问数据,但是堆内因为GC原因Java对象的内存地址不是固定不变的。
每个Task内部最多支持8192个内存页,单个内存页上限是16GB,所以单个Task最多支持140TB的内存空间寻址。
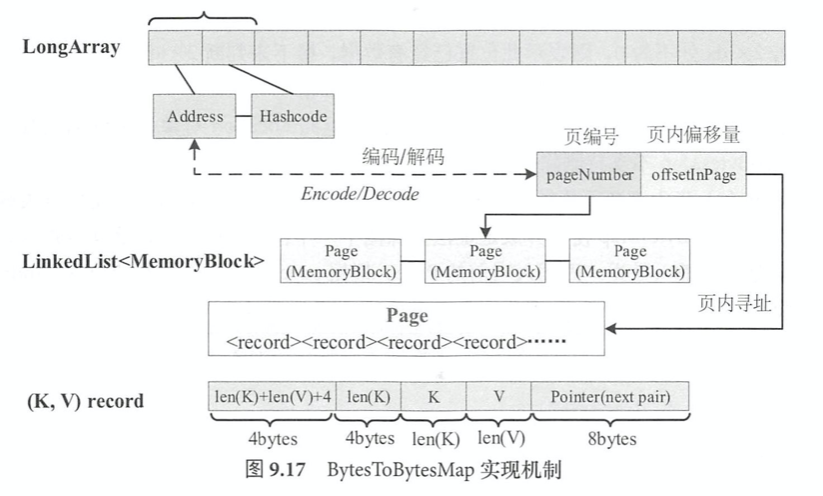
BytesToBytesMap
相比JDK的HashMap,能有效降低JVM对象存储占用的空间和GC开销。对于每条记录,LongArray会占用两个long分别存放这条记录的fullKeyAddress和hashcode信息。每条记录又包含5部分信息,以及其空间占用大小。
UnsafeShuffleWriter/ShuffleExternaSorter/ShuffleInMemorySorter
Tungsten Shuffle的写操作由UnsafeShuffleWriter完成。和常规的SortShuffleWriter的不同之处在于UnsafeShuffleWriter不涉及数据的反序列化操作。UnsafeShuffleWriter里面维护着一个ShuffleExternalSorter来外部排序,当UnsafeShuffleWriter在逐条写入RDD的(K, V)记录时,首先会由Partitioner根据K得到partitionId,并将K和V序列化写入ShuffleExternalSorter.
在写入一条数据到ShuffleExternalSorter中,会先检查能否插入到inMemSorter中。如果inMemSorter数据量达到阈值,会先进行spill操作。之后会看是否扩充LongArray,再检查当前内存空间能否存储新的数据,如果无法满足则ShuffleExternalSorter会申请新的内存页。写入数据时,由TaskMemoryManager编码得到数据指针recordAddress,与partitionId一起作为参数插入到ShuffleInMemorySorter中。
ShuffleInMemorySorter的LongArray数组中存放的是编码后的数据(recordPointer, partitionId). 其中24位表示分区的编号,13位表示内存页的编号,剩下27位表示页内偏移量。因此每个task最大内存是1TB。内存数据的排序有两种,RadixSort和TimSort。Radix需要和used memory相等的作为buffer,而Tim sort只需要used memory的一半作为buffer。spill由UnsafeSorterSpillWriter完成,完成数据的写入后,会对spill操作进行合并。如果使用了压缩,需要压缩算法支持SerializedStreams连接,可以直接、简单地将相同分区的压缩数据连接到一起,且不用解压和反序列化操作。