
Cache-aware computation
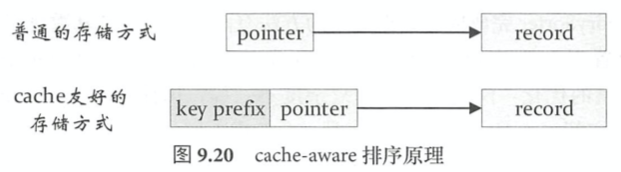
Tungsten cache-aware computation通过设计缓存友好的数据结构来提高cache hit和cache locality,主要针对排序。常规做法每个record有一个指针指向该record,直接访问实际数据的话都是memory random access,cache locality很差。缓存友好的方式是把key的前缀和record指针放在一起。
Code generation
传统数据库都是Volcano模式,每个物理关系算子反复不断地调用next函数来读入数据元组作为算子的输入,经过表达式处理后输出一个数据元组的流Tuple stream. 每次处理一个Tuple时,next都会被调用,数据量非常大时,调用的次数会非常多。next函数通常实现为虚函数或者函数指针,这样每次调用会引起CPU中断,并使得Branch Prediction,因此相比常规函数调用代价更大。
Vectorization是一种处理方式,但是会丢失pipelining data这一个优点。为什么要codegen?
- Virtual function calls
- Branches based on expression type
- Object creation due to primitive boxing
- Memory consumption by boxed primitive objects
Janino是一个运行时的嵌入式编译器,能把编译后的字节码直接加载到同一个JVM运行。
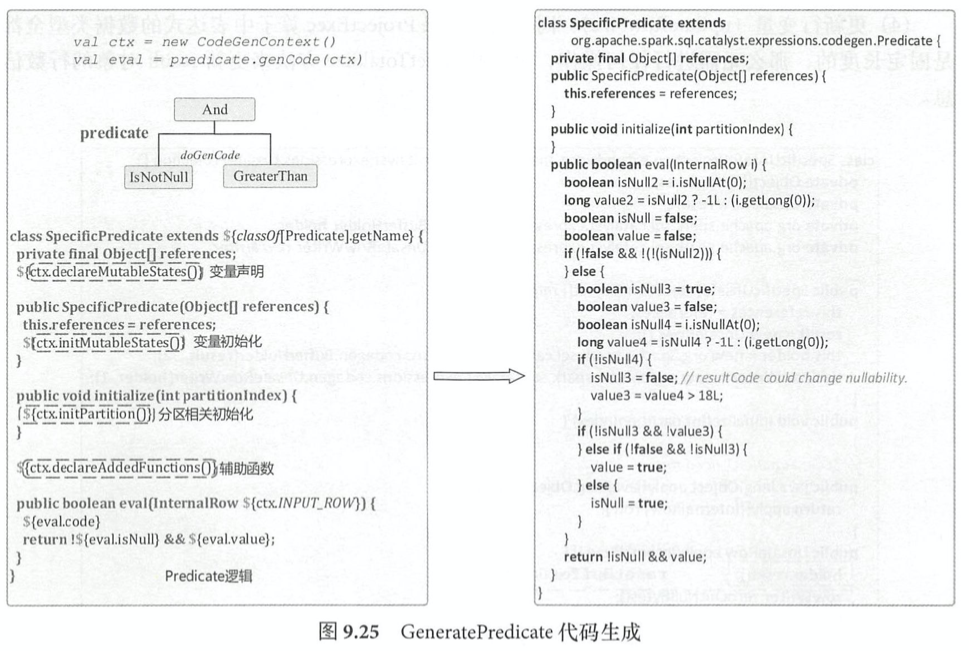
Expression Codegen
Tungsten代码生成分为两部分,一部分是expression codegen,另一部分是whole stage codegen,把多个处理逻辑整合到单个代码模块中。
生成代码中所有变量mutables,类型为三元字符串(javaType, variableName, initCode). 以下面的SQL为例:
select name from student where age > 18

WholeStageCodegen
在遍历物理算子树时,在碰到不支持代码生成的节点时,会在其上插入一个名为InputAdapter的物理节点进行封装。这些不支持代码生成的节点可以看作分割的点,可将整个物理计划拆分成多个代码段,而InputAdapter可以看作对应WholeStageCodegenExec所包含子树的叶子节点,起到InternalRow的数据输入作用。
如图,代码生成可以看作两个方向相反的递归过程:代码整体框架由produce/doProduce方法负责,父节点调用子节点;代码具体处理逻辑由consume/doConsume方法负责,由子节点调用父节点。
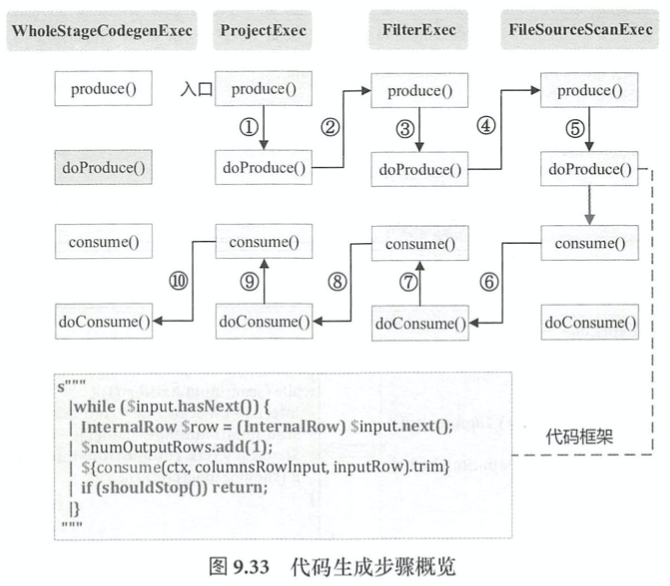 完成三个方面的功能:
完成三个方面的功能:
- 生成下一步逻辑处理的变量inputVars,类型为Seq[ExprCode],不同的变量代表不同的列
- 生成rowVar,类型为ExprCode,代表整行数据的变量名
- 在构造上述对象的过程中,相应修改CodegenContext对象中的元素
Expr Code: Java source for evaluating an [[Expression]] given a [[InternalRow]] of input.