
SIMD advantages: Significant performance gains and resource utilization if an algorithm can be vectorized SIMD disadvantages: Implementing an algorithm using SIMD is mostly a manual progress; SIMD may have restrictions on data alignment; Gathering data into SIMD registers and scattering it to the correct locations is tricky and/or inefficient
-
posts
-
[En][Learning][CMU 15721] Vectorized Execution and Vectorization vs. Codegen
-
[En][Learning][CMU 15721] Database Compression & Storage Layout
I/O is the main bottlenecks if the DBMS has to fetch data from disk. Key trade-off is speed vs. compression ratio
-
Spark SQL内核剖析(5) Codegen
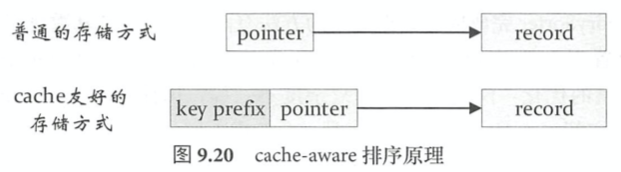
Cache-aware computation
Tungsten cache-aware computation通过设计缓存友好的数据结构来提高cache hit和cache locality,主要针对排序。常规做法每个record有一个指针指向该record,直接访问实际数据的话都是memory random access,cache locality很差。缓存友好的方式是把key的前缀和record指针放在一起。
-
Spark SQL内核剖析(4) 内存管理
Tungsten旨在从内存和CPU层面对Spark的性能进行优化,主要包括3个方面:memory management and binary processing, cache-aware computation, code generation.
-
Spark SQL内核剖析(3)
select id, count(name) from student group by id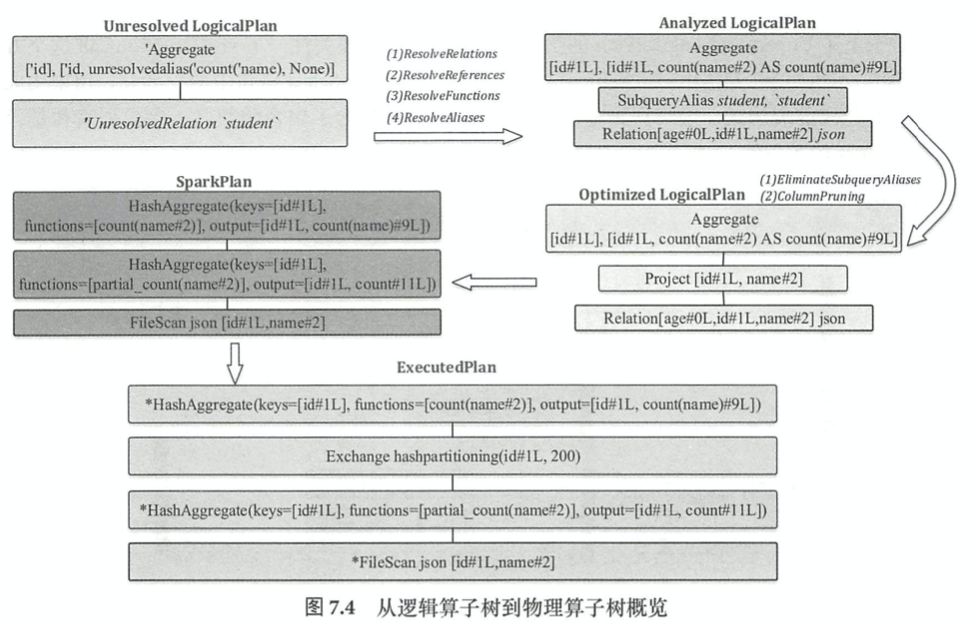 Aggregation有三个策略:
(1) planAggregateWithoutPartial
(2) planAggregateWithoutDistinct
(3) planAggregateWithOneDistinct
Aggregation有三个策略:
(1) planAggregateWithoutPartial
(2) planAggregateWithoutDistinct
(3) planAggregateWithOneDistinct -
Spark SQL内核剖析(2)
Logical Plan
在Spark SQL系统中,Catalog主要用于管理各种函数信息和元数据信息(数据库、数据表、数据视图、数据分区与函数等)的统一管理。包含:
-
Spark SQL内核剖析(1)
DataFrame和RDD相比多了数据特性,拥有Schema信息;而Dataset进一步提供了类型安全和面向对象的编程接口。
-
[En][Paper Reading][VLDB ’20] Magnet: Push-based Shuffle Service for Lareg-scale Data Processing
Introduction
Magnet addresses a key shuffle scalability bottleneck by merging fragmented intermediate shuffle data into large blocks, and provides further improvements by co-locating merged blocks with reduce tasks.
-
[En][Reading] _Effective Java_ item 10 - 19
Obey the general contract when overriding equals
Must satisfy: reflexive, symmetric, transitive, consistent. There is no way to extend an instantiable class and add a value component while preserving the equals contract.
- Use the == operator to check if the argument is a reference to this object.
- Use the instanceof operator to check if the argument has the correct type.
- Cast the argument to the correct type.
- For each “significant” field in the class, check if that field of the argument matches the corresponding field of this object.
-
[En][Paper Reading][ICDE' 19] Presto: SQL on Everything
Use Cases
Interactive Analytics
Individual clusters are required to support 50-100 concurrent running queries with diverse query shapes, and return results within seconds or minutes. Users are highly sensitive to end- to-end wall clock time, and may not have a good intuition of query resource requirements. While performing exploratory analysis, users may not require that the entire result set be returned. Queries are often canceled after initial results are returned, or use LIMIT clauses to restrict the amount of result data the system should produce.
-
量化投资学习(一)
大数定律, 有统计优势。策略比平均水平要好,长期来看一定赚钱,风险要控制好。
-
[En][Learning][CMU 15721] Query Compilation & Code Generation
-
[En][Learning][Spark Summit] Cosco: An Efficient Facebook-Scale Shuffle Service | SOS - Optimizing Shuffle
-
[En][Paper Reading][CIDR' 05] MonetDB/X100: Hyper-Pipelining Query Execution
How does CPUs work
(1) One instruction can have dependency on a previous instruction. (2) Branch prediction. A selection operator on data with a selectivity that is neither very high nor very low, are impossible to predict and can significantly slow down query execution.
-
[En][Paper Reading][SIGMOD' 18] Computation Reuse in Analytics Job Service at Microsoft
The shared nature of analytics job services across several users and teams leads to significant overlaps in partial computations, i.e., parts of the processing are duplicated across multiple jobs, thus generating redudant costs.
-
[En][Learning][CMU 15721] Query Execution & Processing
Optimization goals:
- Reduce Instruction Count
- Reduce Cycles per Instruction
- Parallelize Execution
-
[En][Paper Reading][Sigmod '17] Access Path Selection in Main-Memory Optimized Data Systems: Should I Scan or Should I Probe?
The advent of columnar data analytics engines fueled a series of optimizations on the scan operator. New designs include column-group storage, vectorized execution, shared scans, working directly over compressed data, and operating using SIMD and multi-core execution. This paper compares modern sequential scans and secondary scans.
-
[En][Reading] _Effective Java_ item 1 - 9
Consider static factory methods instead of constructors
One advantage of static factory methods is that, unlike constructors, they have names. Also static factory methods can avoid the restriction that a class can have only a single constructor with a given signature.
-
读《定投十年财富自由》
最近迷上了听喜马拉雅,感觉是对空闲时间非常不错的利用。这一周我听了《定投十年财富自由》,一本书名听起来非常浮夸和智商税的书。
-
一次滑雪途中的Brain Teaser合集
今年圣诞我和我的高中同学F神组了个滑雪局去Heavenly滑雪。路上F神提出玩Brain Teaser, 我们在路上和饭局上思考和讨论了很多题目,令我眼界大开,深深地感到了数学和抽象思维的巧妙。
-
[En][Paper Reading][VLDB ’11] Efficiently Compiling Efficient Query Plans for Modern Hardware
Nowadays query performance is more determined by the raw CPU costs instead of I/O as memory grows. The classical iterator style query processing technique is very simple and flexible, but shows poor performance on modern CPUs due to lack of locality and frequent instruction mispredictions.
-
[En][Paper Reading][EuroSys ’18] Riffle: Optimized Shuffle Service for Large-Scale Data Analytics
Data transformations for grouping and joining data require all-to-all data transfers - called shuffle operations, are becoming the scaling bottleneck when running many small tasks in multi-stage data analytics jobs. The bottleneck is due to the superlinear increase in disk I/O operations as data volume increases.